Alek Westover
Cache Behavior Matters!
Alek: Wow Cache Behavior really matters !!!
Rand: yup! but knowing cache size doesn’t sometimes
How is an array stored in memory?
In C/C++ if you want to access an element of an array you can do so by just incrementing a pointer to the start of the array.
int N = 10;
int* arr = (int*)malloc(sizeof(int)*N);Let’s look at arr, arr+1, \(\ldots\):
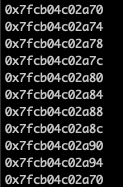
So pointers are really big hex numbers that reference some location (address) in memory. Because sizeof(int) = 4 each of the integers in the array I allocated is located 4 bytes appart in memory.
If I had instead allocated an array of bools, then the pointers to each entry in the array would look like this:
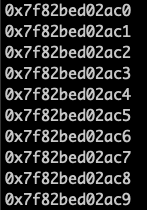
The main takeaway is that the values in an array are stored right next to one another.
And it turns out that when a computer moves data from main memory into cache (memory that can be rapidly acessed), it moves data not as individual elements, but as “cache lines”, or collections of elements.
What is Cache?
Cache is a small amount of memory close to the CPU that can opperate much faster than main memory. The reason cache is small is because it is made of a more expensive material than the rest of the memory. The relatively small amount of data in cache can be accessed very fast.
Whenever a program tries to read in some new data, two things can happen:
- A cache hit occurs if the desired data is already stored in Cache. In this case it is really fast to access the data
- A cache mis occurs if the desired data is not already loaded into Cache. In this case the data must be loaded into cache from main memory, which takes a while.
When new data is put into cache, old data that is already in the cache must be evicted. The standard way to do this is with the “Least Recently Used” or LRU method. This mandates that the piece of information that was least recently accessed in cache will be evicted when new data needs to be placed in cache.
Remark. In a sense this isn’t optimal. The optimal eviction pollicy “OPT” is to evict the piece of data that will be needed farthest in the future. However this eviction strategy is “omniscient” which is unrealistic. However, the resource augmentation theorem says that LRU is competitive with OPT if LRU is allowed a slightly larger cache, so LRU isn’t so bad.
Cache efficiency can have a large impact on a program’s performance
Cache efficiency
Cache efficiency comes in 2 basic flavors:
- Temporal Cache Efficiency: refers to making multiple accesses to the same cache line at times that are close to one another. If the access times are close, then the data is likely still in cache, so no cache miss will occur when the data is accessed again. On the converse side, this means that performing multiple passes over data, and thereby accessing the same element at multiple different times, is detrimental to performance in terms of cache behavior.
- Spatial Cache Efficiency: refers to making multiple requests for data in a single cache line. If the cache line is already loaded into memory, then subsequent requests for data in the same cache line will not lead to cache misses.
Remark. Out-of-place algorithms are not very spatially cache efficient.
Cool Examples!!
At this point you might be thinking “big deal, there is this theoretical idea about good algorithm design. OK, doesn’t affect me.” But it could.
A really cool illustrative example is that of the following 2 simple matrix multiplication programs.
Remark. In this example I will think of matrices as 1D arrays. If you are a mathy person this is because \[\mathbb{R}^{N\cdot N} \cong \mathbb{R}^N\times\mathbb{R}^N.\] If not, it’s because I can think of a matrix as a flattened vector. If I have a 2D array A, and a flattened version F of A then I would get A[i][j] as from F as A[i][j] = F[N*i + j].
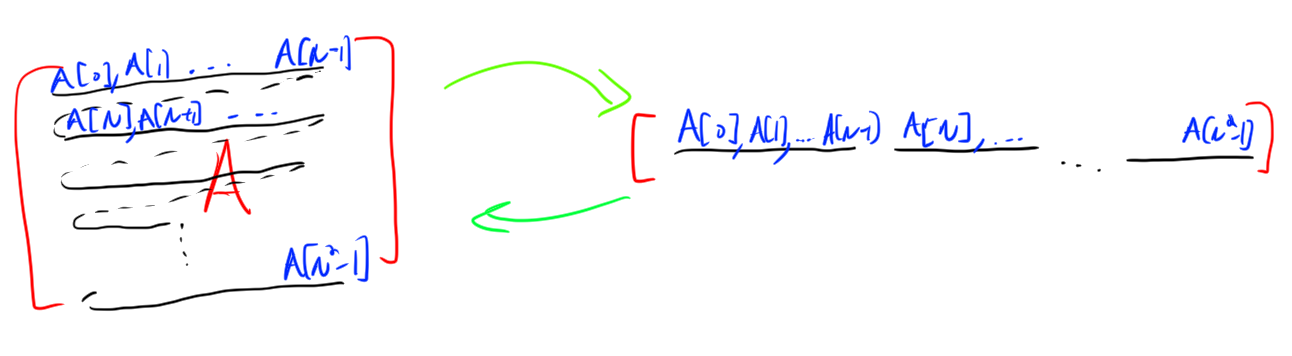
Note that in memory, a multidimensional array is actually represented in exactly this way, the entries in the same row of the matrix are right next to each other in memory, but the entries in different rows, even if they are in the same column, are at least N apart.
Example. The naive way to square a matrix A is just to do it:
#include <cstdlib>
#include <ctime>
int main(){
srand(time(NULL)); // random seed
// randomly initiallize the array A
int N = 1<<9;
int* A = (int*)malloc(sizeof(int)*N*N);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
A[i*N+j] = rand()%1000;
}
}
// allocate room to store the product
int* A_squared = (int*)malloc(sizeof(int)*N*N);
// square A
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
int sum = 0;
for (int k = 0; k < N; ++k) {
sum += A[i*N+k] * A[k*N+j];
}
A_squared[i*N+j] = sum;
}
}
return 0;
}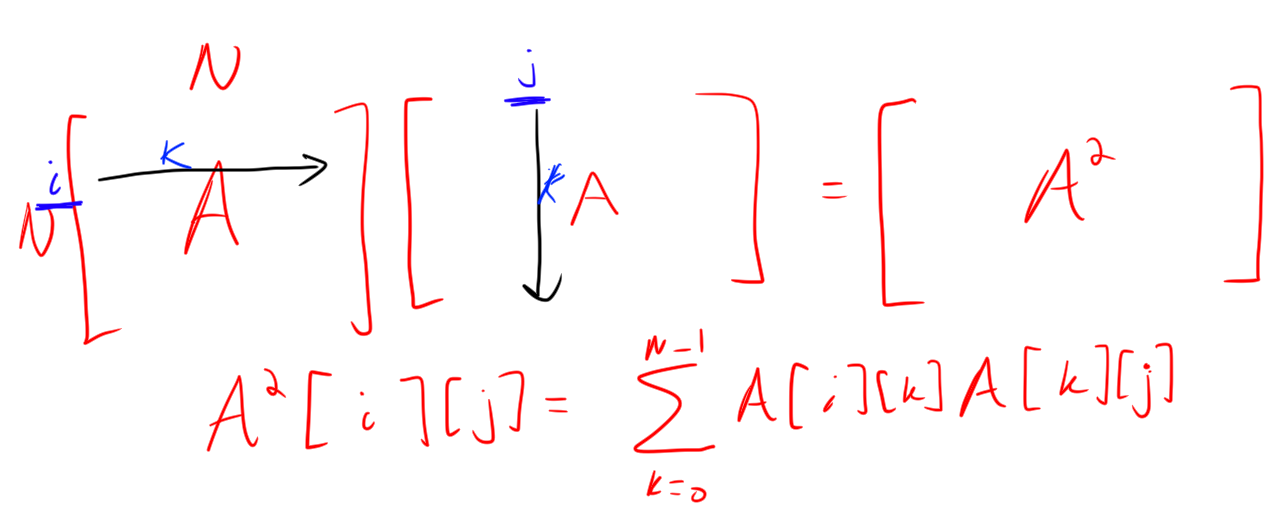
However, this is making one big mistake: in the inner loop each A[k*N+j] for different values of k is in a different cache line. So this program suffers from cache inneficiency. Is it a big deal?
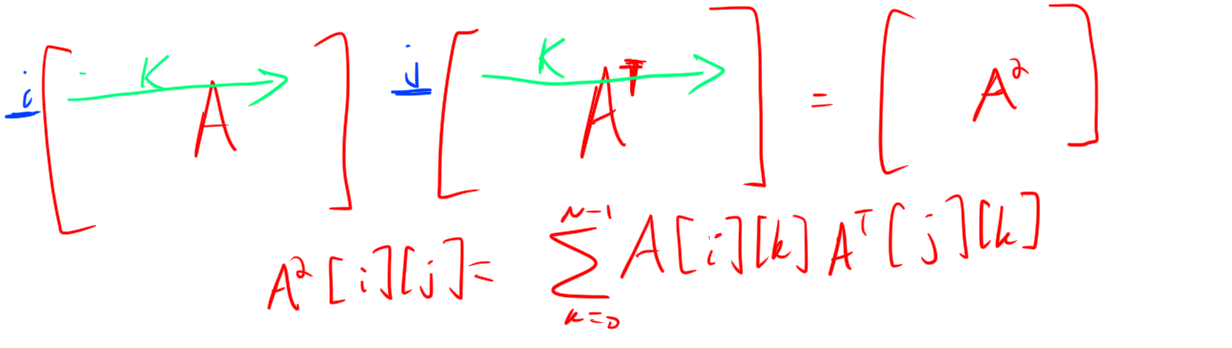
Example. To see if this really matters, we can make a version of the matrix squaring program that is more cache efficient, by storing the transpose of the matrix A as pre-processing. This is \(O(N^2)\) extra pre-processing, but the algorithm is O(N^3), so this could concievably help if the cache misses are a big deal. Here is the code
#include <cstdlib>
#include <ctime>
int main(){
srand(time(NULL)); // random seed
// randomly initiallize the array A
int N = 1<<9;
int* A = (int*)malloc(sizeof(int)*N*N);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
A[i*N+j] = rand()%1000;
}
}
// store A transpose
int* A_transpose = (int*)malloc(sizeof(int)*N*N);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
A_transpose[i*N+j] = A[j*N+i];
}
}
// allocate room to store the product
int* A_squared = (int*)malloc(sizeof(int)*N*N);
// square A
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j) {
int sum = 0;
for (int k = 0; k < N; ++k) {
sum += A[i*N+k] * A_transpose[j*N+k];
}
A_squared[i*N+j] = sum;
}
}
return 0;
}
Performance analysis: The perforance difference is stunning. When both where run (without any optimizations, i.e. compiled without O3) on arrays of size 1024 time recorded:
- For the naive program:
./a.out 15.78s user 0.07s system 99% cpu 15.970 total - For the cache concious algorithm:
./a.out 3.35s user 0.03s system 98% cpu 3.432 total
The cache concious program is 5 times faster (on my computer on this input)! Wow!! Neat!!