A lot of people have asked me lately “what cool stuff have you been learning in your deep learning class”? I haven’t had a very good answer. In this post I plan to discuss some stuff that we’ve talked about and highlight some things that I have found cool. Will serve the triple purpose of (1) helping me solidify understanding of various deep learning things, (2) sate (or maybe stoke!) the curiosity of friends interested in what I’m learning, (3) serve as conversation fodder.
1 Diffusion
- it’s pretty easy to add a little bit of noise to an image
- so we can make lots of data pairs of the form IMAGE, IMAGE + a little bit more noise
- so we can learn the reverse direction.
This is a fake shoe!

2 VAEs
We have some complicated data distribution
But we’re going to model our data as being a simple function applied to some latent variables, where the latent variables are actually Gaussian.
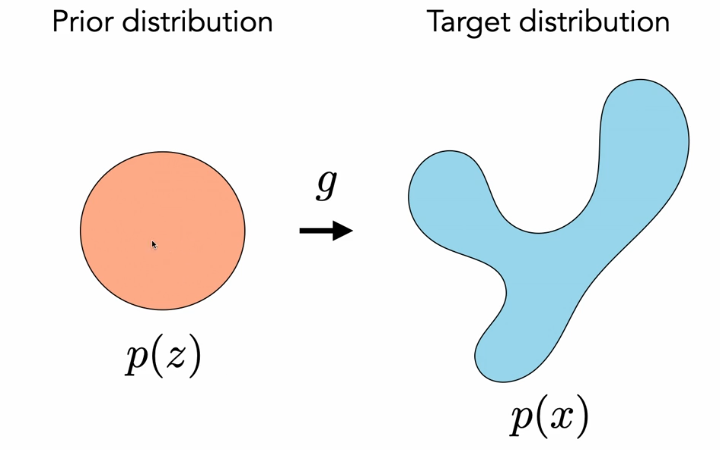
This will give us a generative model.
Specifically, we can sample
VAEs are going to be similar to AE’s but an AE is more like this:
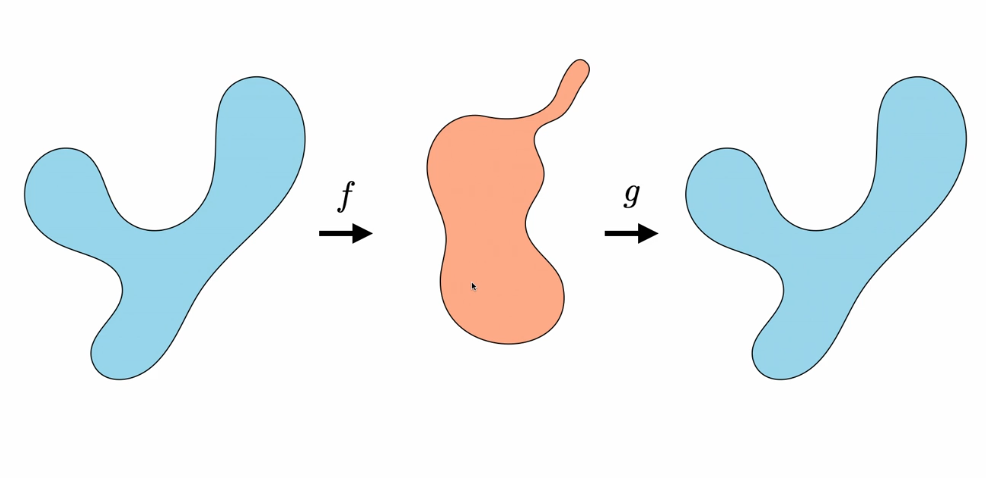
Ok, so how are we going to learn the encoder and decoder?
Let’s call the encoder
. .
The things that we want are:
- If we do
then (in euclidean dist). for .
In other words, if we encode to a latent rep of a point, then when we decode back that latent rep we should get about the same thing that we started with, and also we want the latent reps to live in a nice unit bubble around the origin.
You can write down some loss function that drives us to achieve both of these things, although these things are in tension so we’re not going to be perfect — reps that are more squished are harder to decode.
You might say “why do we even need an encoder?” The reason is that we are going to do importance sampling to estimate an integral.
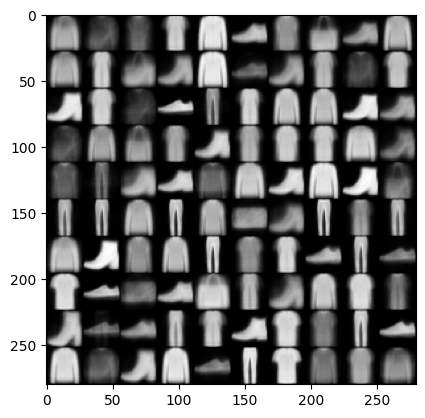
On our homework we had some data that looked vaguely like this (actually this is fake data generated by my VAE, which you can probably tell bc some of the items look kind of sus. But it mostly looks believable).
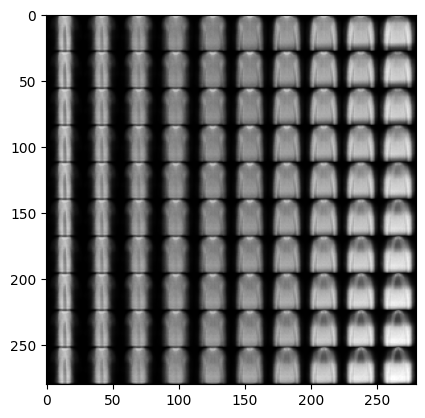
It learns “interpretable” directions in the latent space!
- here’s what happens if we just vary one coordinate in latent space at a time.
I had quite a bit of trouble training this.
My intuition is that lots of optimization problems where you have two fighting objectives (e.g., VAEs, GANs) suffer from a similar sort of instability.
For me, I finally got it to work by setting the loss to be 100*reconstruction_loss + KL-divergence. I’m pretty proud of the 100 — I was debugging and realized that the KL divergence, despite being really small, was somehow still taking over the gradients, and the reconstruction loss just wasn’t improving. Maybe I just needed more epochs but idk.
Anyways, I turned up the heat by which I mean I multiplied the reconstruction gradients by 100 and then my little VAE obligingly learned some reasonable latent representation of FashionMNIST.
3 Why does deep learning find general circuits?
Supervised learning initially may seem kind of magical — sure neural networks are universal function approximators, so of course we can get them to fit some training data, but why do they generalize to unseen data?!!
One thing that some people say is:
Neural networks are super huge, so when you randomly initialize them, they’ll have all the simple circuits. When you train a neural network, you’re pruning away the garbage and revealing the simple underlying circuit.
To be a bit more precise, it’s more like this:
- Models start by memorizing the training data, and maybe having a little circuit that generalizes but isn’t used too much
- If you’re using weight decay — intuitively, this means penalizing the model for being too complicated and spiky — then it’ll end up amplifying a simple circuit over time.
Neel Nanda has some really cool work on Grokking with Modular addition that gives some good evidence for this hypothesis.
- basically what happens in his setup is that the training loss drops really fast because the model memorizes
- but the test loss doesn’t get good at that point because generalization didn’t happen yet
- then slowly the model unearths a solution that generalizes.
- this gives modest boost to training performance because we apply weight decay
- but it makes a huge difference on the test set.
I think that’s a pretty neat idea.
A phenomenon related to this is “grokking” — when a model suddenly, after having loss plateued for quite a while, starts doing much better.
- If you’re worried about models developing dangerous capabilities then grokking might seem pretty scary — it’d indicate that a LLM could, over a very short period of time, suddenly get extremely good at hacking or something.
- However, this is maybe something that you could handle — it seems possible that you could detect when a model is starting to grok a new concept, and could develop continuous measures of capabilities progress as opposed to benchmarks which always just go from zero to saturated over the course of 1 model. Interesting research direction!
 Adam’s excellent mathematical explanation of why this happens
Adam’s excellent mathematical explanation of why this happens
4 Unsupervised / semi-supervised stuff
Unsupervised learning and semi-supervised learning is pretty cool.
Before this class I guess I thought that unsupervised learning just meant “do kmeans clustering”.
But this doesn’t really make sense — usually the challenging part would be to learn semantically interesting features! clustering once you have such features is the easy part.
But there’s some pretty nice techniques for doing this.
Basically contrastive learning seems like the main really good approach.
- for instance, if you want to in an unsupervised manner cluster shapes, you could
- create contrast pairs where you say “two shapes are similar if I obtain one by translating the other, or modifying it in some small way, and different otherwise”
6 Transformers
Transformers are pretty interesting. I’ve given really garbled explanations of what they are doing a couple of times, and so here is an attempt at a better explanation.
Disclaimer — I’m going to describe a conceptually clean way of thinking about what a transformer does. At some level a transformer is just a giant stack of matrices and doesn’t have to act like I’m about to say it acts. However, (1) I think that this is a really helpful way of thinking about what a transformer does, and (2) as discussed above, NNs often do actually learn simple circuits. One thing that can complicate this is superposition. (3) I’m not aware of any experiments that support the following way of thinking about transformers. But I believe that at least some parts are true and could be experimentally verified, and probably have been. ok, that’s a lot of disclaimers. Anyways.
Let me describe BERT “Bidirectional Encoder Representations from Transformers”.
Specifically I’ll discuss BERT-base (not BERT-large).

A helpful graphic.
First, what does BERT even do?
BERT is trained to do “Masked Language Modelling”. Which means, you have a sentence, mask some tokens, and then ask it to predict those. The reason you’d want to do this task is actually just because it forces the model to learn really rich representations of sentences that are useful for downstream tasks.
What’s the architecture of BERT?
- 12 layers — a layer consists of an attention mechanism followed by an MLP.
- sequence length / context size — 512 tokens
- hidden dimension — 768
- number of attention heads — 12
- total parameters: 110M
For reference GPT4 probably has about 500B parameters, and the human brain has about 100T axons. So BERT is tiny. Figures! It’s already about 6 years old!
Anyways, what happens inside an attention block?
So, basically you have a sequence of token embedings, which you can think of as “deep representations” of the input tokens. A multiheaded attention unit is composed of multiple heads. You can think of these heads as all serving different purposes.
For instance, ChatGPT recomended I think about it like this:
- Head 1: Might focus on local syntax—for example, recognizing dependencies like subject-verb-object relationships.
- Head 2: Might capture semantic similarity, such as grouping words that are related in meaning, like “cat” and “animal.”
- Head 3: Could focus on positional information, such as which words are nearby in the sequence, attending more to adjacent tokens.
- Head 4: Could attend to global context—long-range dependencies that span across the sentence, like connecting the start of a sentence to its end.
What does a single head do?
Each token embedding
One other thing to note is that residual connections are pretty important, and that thinking of attention heads as writing to a residual stream seems reasonable.
Also positional embeddings are pretty important.
7 misc
- autograd is extremely nice.
- Why deep networks are good: some things would require exponentially wide shallow networks, but admit very not super wide deep networks
- you should use Kaiming’s initialization for your weights.
- you should use weight decay = .03 and LR=.001
- einops is pretty nice
- inductive biases are extremely important, especially for generalization
- Often you have some task, and maybe you have not so much data for this task. But skills often transfer between tasks. So if you can get good at one task then that’s often helpful for other tasks.
- An 80GB H100 costs $40,000 and uses 700W of power — that’s about the same as a toaster!! However, if you are OpenAI and want 50,000 of these H100’s, then that’s a freaking lot of toast.
Here’s a creepy toaster drawn by ChatGPT:

- transformers are super data agnostic — this is great for multi-modal applications!
- I’m pretty excited about my transformer shortest paths project.
- I’m also pretty excited about some model organisms work that I’m going to do soon.
tag:none