Remark: None of the ideas in this note are original. They are mostly extremely basic statistics.
Here’s a simple model for an evilness detector
We can get a classifier by fixing any threshold
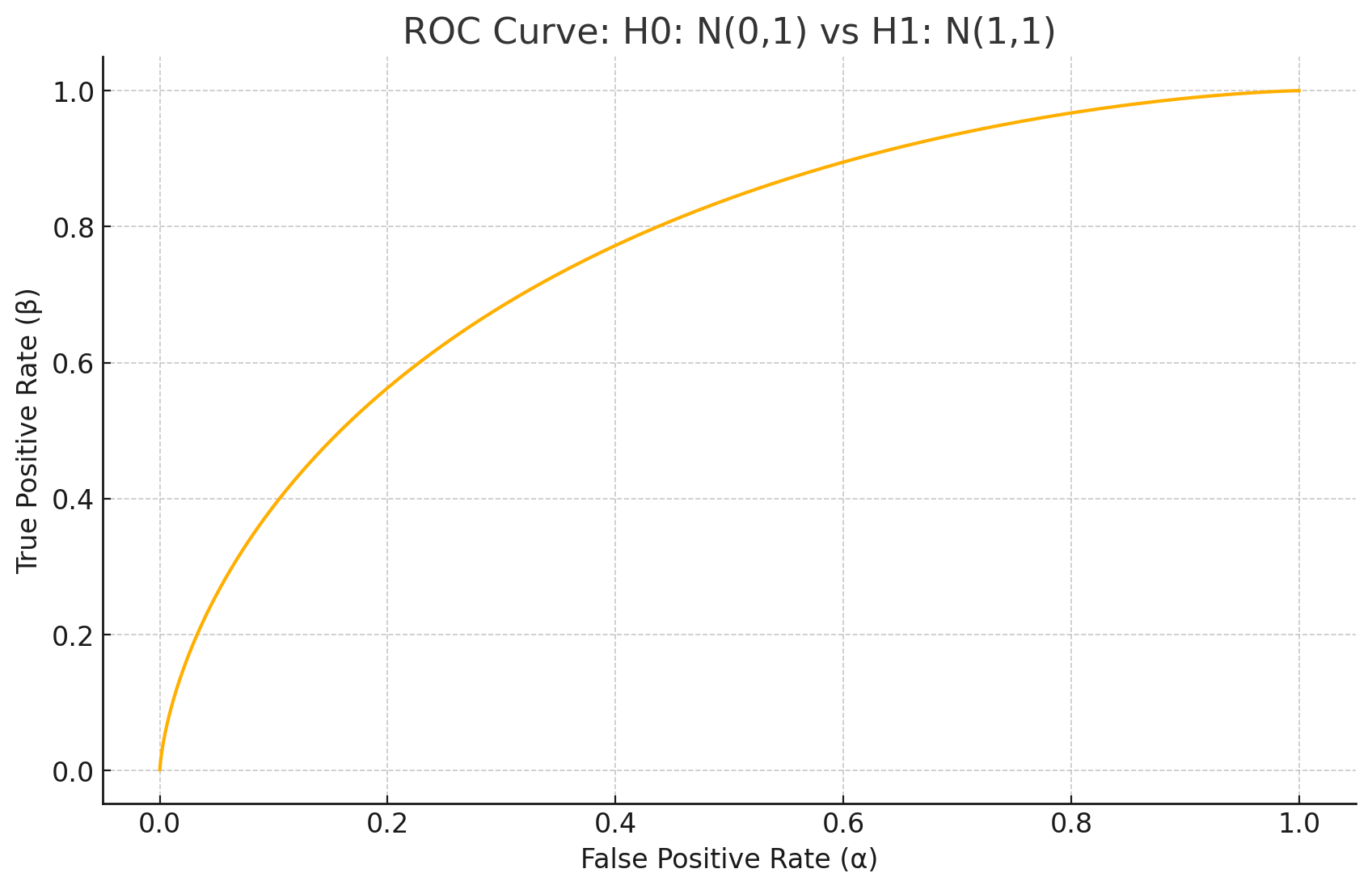
Here’s a slightly more complex scenario:
You have metrics 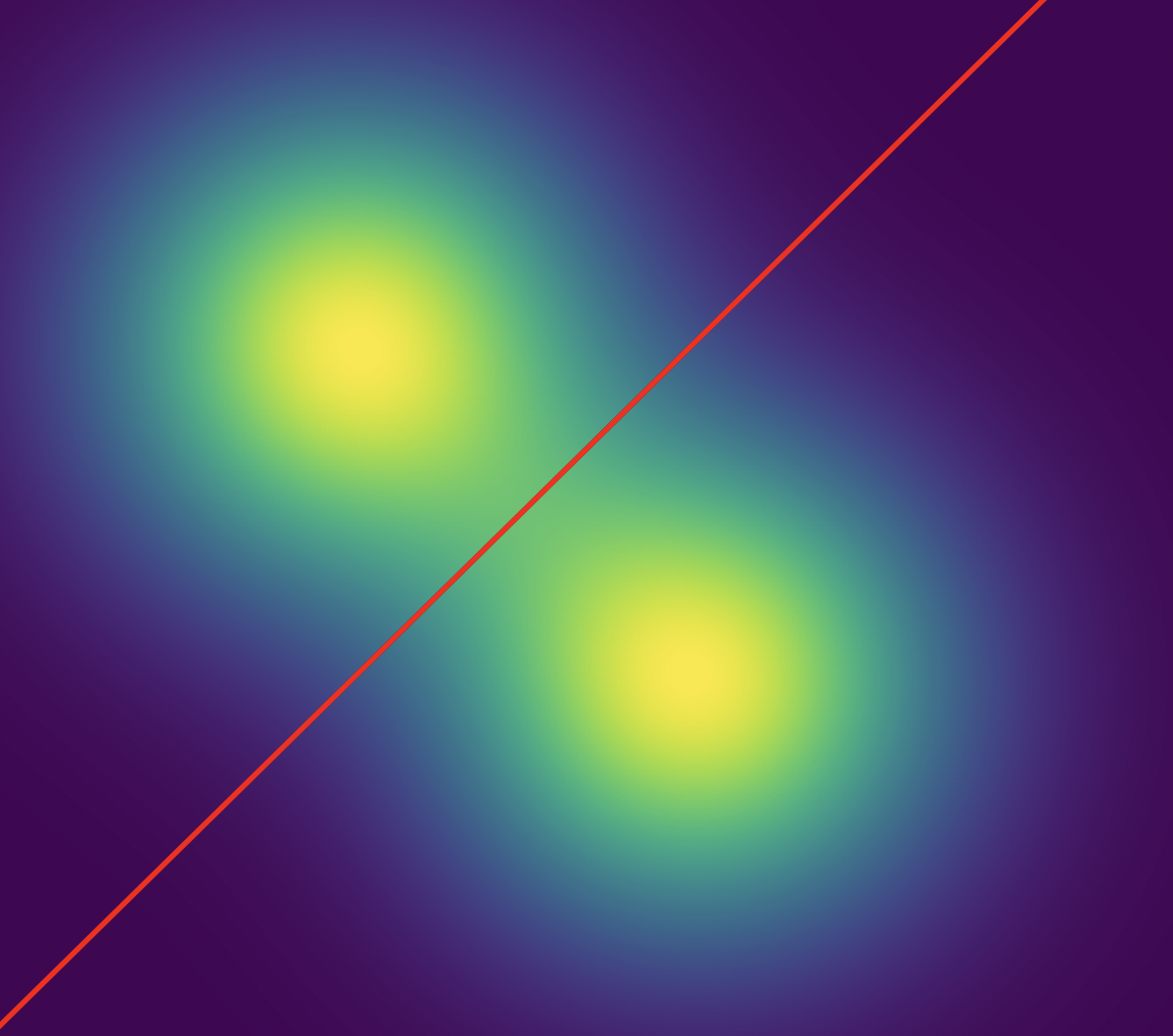
In this case, the family of classifiers that give the ROC curve is (again) given by choosing a hyperplane, whose normal vector is the line connecting the center of the evil and benign distributions,

If you have
More generally, you might imagine that
- Sweep the likelihood ratio that you care about.
- Analytically compute the likelihood ratio of points to put them on either side.
- This gives you your ROC curve.
Even more generally, you might assume that
Distribution shift
The assumption that we know can get a bunch of samples from the detectors under the benign and evil states is pretty questionable.
Here’s an attempt at making a more realistic setup. It will still be extremely toy.
Suppose you have bits
But in actuality, there is some subset
We now have a crisp theoretical question:
The AI then chooses a strategy
for how it’ll set the subset of the detectors that it has control over. Then, the human chooses an evil vs benign classifier . We’ll assume that the AI doesn’t know (we are assuming that the AI can’t change based on ). Then, the human is either handed sampled from OR, the human is handed where 80% of these values are sampled from , and the remaining 20% of values are set by (you can decide whether or not gets to see the rest of the bits, I think not seeing them is maybe more natural). The human then runs their classifier on and outputs “benign” or “evil”. For every value of , you’d get an ROC curve. You could take over the values of to compute your “guaranteed ROC curve.”
Unfortunately, this seems like probably the wrong question, and not very productive to think about.
A less pessimistic assumption that you could make is some kind of non-adversarial distribution shift. If you make that assumption then it seems like a reasonable idea to just flag things which are far OOD from the benign distribution, even if they’re closer to the benign distribution than the evil distribution.
You shouldn’t spend too much of your FPR budget on this, but plausibly it’s worth spending some of your FPR budget on this. Like 1%.