These are some notes on fine grained complexity theory, from Ryan + Virginia’s class. I am not actually taking the class, but am reading the notes. These are now also notes from Ronitt’s Sublinear time algorithms class. I actually am taking this class, but have chosen to digest the material mostly at my own pace. I enjoy having occasional readings about cool algorithms and some occasional problems to work on, and an excuse to think about permutation avoidance again.
I will abbreviate fine grained to FG and sublinear time to SL.
FG lecture 1
Theorem: SETH implies OV
Proof
Let
Theorem
Proof
Three part graph.
Left: vertex for each vector
Edges:
Connect vector to the coordinates where it has a
Also add two “star” vertices. Left star vertex has edge to all middle vertices, left vectors and other star Right star vertex has edge to all middle vertices, right vectors and other star.
Then diameter is either 2 or 3. 3 iff orthogonal pair.
lecture 2
Theorem Dominating set in
Proof:
multipoint evaluation
We can evaluate a polynomial at
interpolation
Given
multiplication
You can multiply degree
3-sum on small magnitude numbers
Theorem
Suppose we have a 3-sum instance where the numbers lie in
4-Russians
Matrix vector multiplication with pre-processing.
Break into blocks. For each block, Store
lecture 2 again, but different
ETH: 3-sat requires
independent set
Example:
Encoding a 3SAT instance as an indepset instance.
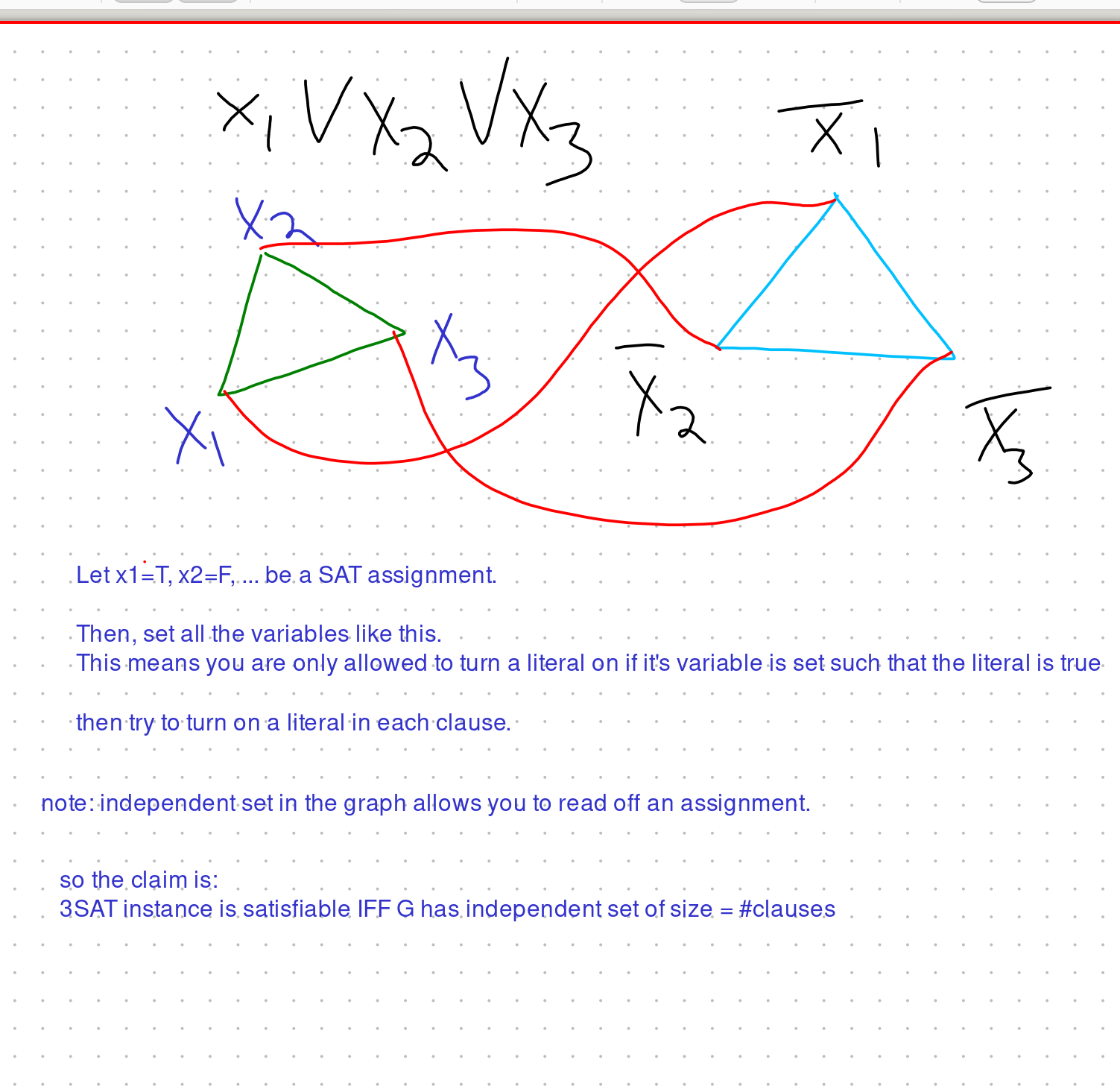
Problem: this doesn’t let us prove an exponential lower bound because we blew up the problem instance too much.
Like you start with a n var m clause 3SAT instance, and produce an m vertex graph.
one hope: maybe there is some OP sparsification that we can do.
- probably not.
but, there is this lemma:
IPZ sparsification lemma:
there is a
yup now the IS thing works.
SETH
For all
claim: SETH implies ETH
even stronger claim:
If there is any
Again we use sparsification.
Standard kSAT ⇒ 3SAT reduction:
Turns a n var m clause kSAT instance into a
So first we sparsify. Turn n var m clause ksat into a bunch of n var ~n clause kSAT instances, and then turn these into kn var ~kn clause 3SAT instances.
So if 3SAT were subexponential we would get way too fast of an algorithm for kSAT like this under SETH.
ksum
Theorem: if for all
proof Let’s just work with a sparse formula, by virtue of sparsification lemma. Turns out to be better to work with 1-in-3 SAT (exactly one var in each clause is satisfied to make the clause true). But this only costs us constant blowup to do so its fine.
We do the standard “one-hot encoding” technique. Split the vars into k groups make the numbers:
- have some part of the number to indicate whether you’ve done a partial assignment from each group
- then have some other part for making sure the clauses are all satisfied.
ah this is clever.
Sparsification
OBS: Branching can reduce the number of clauses
for example
- consider the variable that appears in the most clauses
- the fact that we’re not sparse yet means that we can branch and kill some clauses.
SL lec 3
connected components estimation
Algorithm is as follows:
Repeat a couple times:
pick a random vertex v
BFS out of v for at most 100/epsilon steps,
stop early if you exhaust the connected component.
define nhat[v] to be either the size of the connected component that v is in, or 100/epsilon if the connected component is big.
Use the nhat's to guess the number of connected components.
So the key idea behind this estimator is the following observation:
If we let
So we are going to compute some numbers
Actually, we kind of already talked about how to do this above. Anyways.
So,
And then we need to go into some kind of computation to show that if we have a good approximation on average and we iterate a couple times we can get a good approximation with decent pr.
In particular you can just do a Chernoff bound.
Specifically, Hoeffding bound says: if
MST estimation Kruskal’s algorithm says that to find an MST you can do the following stuff:
- add as many weight
edges as is possible. - then do weight
- etc.
This allows us to relate MST estimation to estimating the size of some connected components defined by taking all edges with weight smaller than some threshold.
SL lec4
Today we are going to talk about a sublinear (in
Sparsification lemma
If you sample
proof: We’ll do it below.
Claim:
Once we’ve sparsified the color palettes, we can ignore edges
Proof
For each vertex
Now we give a
Algorithm
- Sample some random colors for everyone.
- Construct sets
which are the set of vertices with color in their palette. - Construct the sparse edge set
as follows: - For each
, - For each pair of vertices
- Add
to if This takes time
- For each pair of vertices
Finally, do the greedy algorithm in this sparse graph.
sparsification lemma
We don’t actually prove the sparsification lemma. we prove something a bit weaker: we allow
- run the greedy algorithm
- show that it fails with
pr at each step - union bound
SL Lec 5
In these notes VC will refer to vertex cover (a set of vertices that hits every edge).
Q: How to approximate min VC size in sublinear time? A: We will give a distributed algorithm for computing a small vertex cover.
More precisely, after running the distributed algorithm, every vertex should raise a flag saying whether or not they wish to participate in the VC.
We work in the LOCAL model of distributed computation.
We let
Distributed Vertex Cover Algorithm
for each edge e:
Initialize x[e] = 1/Delta
for i = 1 ... log_{1+gamma}(Delta) :
for each v that has sum_{edges e incident to v} x[e] >= 1/(1+gamma):
add v to the VC
for all e incident to v:
freeze e
for each unfrozen edge e:
multiply x[e] by 1+gammaClaim 1: This algorithm outputs a VC. pf: Endpoints of frozen edges are added to VC. All edges are eventually frozen.
Claim 2:
We can interpret the final values of
Proof We only increase edge weights if we’re sure that it’s safe to do so. The fact that our VC size is not much larger than the fractional matching size can be seen as follows:
- Suppose we form a sum
by starting at and then adding to whenever we freeze an endpoint of . - Because we freeze every edge eventually, at the end we will have
. - The amount that we increment
by when we freeze edges incident to some vertex is at least by design. - Thus,
.
Claim 3: The value of a fractional matching gives a lower bound on the size of the minimum vertex cover.
pf
This is super obvious for matchings.
For fractional matchings, assign each edge to an endpoint in the VC. Have each VC vertex aggregate its assigned edges weights.
The total weight aggregated by the VC vertices is
SL Lec 6
Last class I think we got a
CAUTION: maximal
In this lecture we will talk about approximating the size of a maximal matching (?)
Let
Claim: a maximal matching has size at least
pf: each edge you take eliminates fewer than
Greedy Maximal matching alg:
- take edges until you can’t take any more
Now we have an interesting idea:
- Imagine we had an oracle that would tell us whether an edge was in the matching.
- Would that help?
For estimation it totally would. We would just sample some vertices to estimate the probability that a random vertex is an endpoint of an edge of the matching.
And we add a bit just to guard against terrible underestimates.
ok fine so this’d be great if we had such an oracle.
Intuitively: maybe we don’t need to actually run greedy to figure out it’s bx on an edge?
Here’s a weird (but useful) recursive way of writing out our greedy algorithm
def matched(e):
for all edges e' adjacent to e that come before e in ordering:
if matched(e'):
return False (e not matched)
return True (e matched)Let’s try seeing how expensive this is if we do a random ordering.
Under a random ordering, the probability of going on some specific path of length
So we can get a
Is this good? Well, I wouldn’t use it unless
FG 09-27
Virginia showed us a neat trick in class today: breaking the problem up into lots of little parts. Specifically, the problem was dynamic reachability and she wanted to give some combinatorial lower bounds based on triangle detection / BMM. And we could get a simple lower bound pretty easily, but chopping up the problem in a nice way let us get a lower bound even with arbitrary polynomial precomputation.
So that was nice.
SL 7
Property testing for graphs:
- “
-far” will mean “can edit ” edges to get in class; here is max degree limit.
Kuratowski theorem
planar iff no K5 or K33 minors
minor = graph obtained by contracting edges
Def
i.e., Remove few edges to break graph into tiny pieces.
Theorem
For all
So we can use the following approach for testing planarity:
- Find a way to remove a small number of edges in order to split G into small CCs.
- If step (1) fails, we know we aren’t planar.
- If step (1) succeeds, we can just check one of these little CCs for whether or not it’s planar.
Similar to what we did for matching last time, we’re going to break the problem into two parts: making a “Partition Oracle” and using a Partition Oracle.
Partition Oracle
- input: vertex
- output: Name of the part of the partition that
belongs to
Require: partitions are small and connected.
Also require: if
It’s pretty straightforward how to do testing once you have such an oracle.
Building the oracle
- global partitioning strategy
- locally implement it
is connected \ - edges connecting
, are at most
Claim: in a planar graph, in any decent partition most nodes have
Global Partitioning algorithm (note: I don’t think we actually do this, this is just how you would in theory glue stuff together?)
order vertices randomly
partition = []
for i in range(n):
if v_i still in graph:
if exists (delta,k)-isolated nbrhd of v_i in remaining graph:
S = this neighborhood
else:
S = {v_i} # hopefully this is unlikely
partition.append(S)
Remove S from graphWe want to show that this algorithm works reasonably well.
Lemma:
A
Proof sketch
Using the hyperfiniteness theorem, we know that there is a partition such that if we rm
For each vertex
By Markov,
So basically the global algorithm is pretty good.
Now, this global algorithm is basically just greedy. So I’m hopeful that if we do the same random ordering trick that we did last time, maybe good things will happen. Like we can cut long range dependencies and just locally simulate the greedy thing.
Local Simulation of Partition Oracle Yeah so the way we do it is indeed just like last time. (this is not to diminish the technique --- on the contrary, I think the broad-applicability of this technique is exciting!) But even having seen last time it took me a minute to see this so let me write it down.
Here’s a recursive version of the local oracle:
# fix a random ordering of the vertices
# input: vertex
# output: a small neighborhood of v that has few edges to the outside world
# note: these neighborhood things need to be **consistent** across calls to the oracle
def oracle(v):
for each vertex w within distance k of v, where w has lower rank than v:
run oracle(w)
if some nearby w already claimed v:
output the part that claimed v
else:
just do a little BFS out of v (respecting the nearby guys who have their own thing going on) and decide on a neighborhood for vRunning time analysis is as follows:
for recursion-y stuff.
(Also, who thought that doubly exponential running time was a good idea?)
(lol I guess think of
Anyways, then we have to do the little BFS thing, but this is just small money in the total running time.
Apparently you can do much better dependence on
property testing lower bounds
Problem:
Given
Claim:
You can’t solve this problem using fewer than
Proof:
Suppose that you had some (potentially randomized) algorithm that could output a vector
Remark:
I’m pretty sure that you actually need
FG — matrices
Solve LCA in
Then just do something easy to get
SL SPANERS
Def:
Remark suppose
This is a proof that
Similar lower bounds for other
Today, we give an LCA algorithm for computing a
First idea: We can delete an edge from every triangle.
For today:
We assume max-degree
First, how would you even do this globally?
- Pick random set
of size - Then,
has neighbor to all high degree vertices. - Now we construct a graph as follows:
- Add all edges touching
- Add all edges touching low degree vertices
- Add ONE edge from
to all adjacent clusters
This graph clearly has a very small number of edges.
Suppose
side remark — I quite enjoy some algorithmic graph theory! brings back some good memories. anyways.
other side remark: in our model of the graph, we allow “degree probe” i.e., asking in constant time what the degree of a vertex is.
Anyways, that was the global algorithm. Now, let me try to guess how I’d local-ify it.
So, in a LCA you have query access to some huge random string that is persistent. Like your algorithm is parameterized by this random string, and just has to work for most choices of this random string.
So ok, each vertex picks whether it’s a center or not. So now it’s pretty easy to pick out the edges touching low degree vertices, and also the edges touching centers. Also, it’s pretty easy for every vertex to choose it’s cluster center that it wants to join — just join the cluster who’s cluster center has the lowest id amongst all clusters that you’re connected to
And then each vertex chooses the lowest id neighbor in each cluster as it’s connection in that cluster. By which I mean, iterate over your neighbors in order, maintain a list of clusters that you’ve already connected to, and take an edge whenever it goes to a new cluster — and ofc at that point you mark that cluster as having been visited.
Ah, but this is kind of expensive, because it already takes like ~
Anyways, let’s think about it.
Type 2 query — asking if an edge
Type 3 query — edge to adjacent cluster??
Anyways, that didn’t quite work so we’re changing things up a bit.
Let
So, now we’re going to connect
now, here are the other edges that we add:
- For each edge
- Let
be the set of neighbors of which are lower id than - For each
, compute and cross off as “we’ve already met” - If by the end of this process there are some things in
that haven’t been crossed off, then we say that the edge is cool and we add it. Else, we don’t add it.
This clearly works, but it’s too slow still
Now finally, here’s the smarter method that’s actually efficient.
Yeah, so we were just being a little bit silly above. Here’s how you can do it fast:
- For each edge
- Let
be the set of neighbors of with lower id than - For each
- For each
- Check if
is a cluster center of — if so cross out - Check whether any
didn’t get crossed out.
This takes time
Maybe later we’ll fix the issue about the max-degree being too large. Oh lol actually we’ll fix it on the homework!
maximal independent set — local computation algorithm
This one had some pretty neat techniques. The main one I liked was, somehow breaking the problem into not-super-overlapping sub-parts.
First, we give a distributed algorithm for the problem.
Each round:
Every vertex randomly tries to color itself with pr 1/(2 Delta)
Coloring "goes through" if no neighbors also try to color themselves
if coloring goes through:
kill the neighborsWe’re going to run this algorithm for
Some ppl will be killed, some will be put in the MIS. But some are still undecided. The number of undecided guys is
So our LCA algorithm for MIS is going to work as follows —
First run Luby for
We will show:
Lemma
Size of CC is less than
Define
Then, if
PLAN
- large CC ⇒ many nodes at dist 3 apart
- nodes at dist 3 apart ⇒ unlikely to simultaneously survive
Still a bit complicated.
CC ⇒ just only think about a spanning tree for the CCs.
CLAIM
For live CC
Pf: greedily construct the tree
By a union bound, and the fact that there aren’t too many possible trees on
degeneracy
Nathan and I came up with a nice algorithm for approximating the degeneracy of a graph. Unfortunately the actual pset question was much less cool than this (it was about arboricity). But anyways here’s our ridiculous algorithm.
First, define degeneracy of a graph to be the smallest number
Observation 1
You can compute degeneracy in time
Observation 2 Now we argue that subsampling edges doesn’t mess with degeneracy too much. The argument is that, if we look at the vertex stripping order from before, then it’s probably still a valid ordering. When you have lots of neighbors in a set, Chernoff says that this number shrinks predictably. And if not then we don’t even care.
cool FG problem
Someone told me this problem today, and I thought it was very nice.
Q: Given a subquadratic algorithm for OV, show how to make a subquadratic algorithm for “all vectors OV” — for every input vector you need to output a bit that tells you whether that vector is orthogonal to one of the other vectors.
A:
- First, let’s find all the vectors
such that there are more than many with . We can do this in time per . - Get rid of these vectors — we output 1 for them.
- Now, partition
into many pieces each, randomly which will be of size . - For each pair of pieces, check with our magical OV algorithm whether there is any orthogonal-ness that happens between the pairs. This takes time
because of our fancy OV algorithm. - For each
piece, we find at most many pieces that can be orthogonal to it. - Now for each
we look at the elements in the union of the pieces that we need to consider and see whether any of these are orthogonal to it.
Neat!
distribution testing
distribution testing part 1 — L1/L2 norm
Claim:
Suppose we take
- If
(uniform) then with Pr . - If
is -far in -norm from uniform, then with Pr .
Proof
Hence,
Hence Markov says Pr of deviation of more than
Messing with the parameters a bit this should give us a tester between
- uniform distr
- L1 Far from uniform distr
L2 distance.
Here’s the strategy:
- Let
. - We will take
samples, and let denote whether samples where for the same value. - We define
. - By linearity of expectation:
- We’ll show that
is reasonable - this will imply that setting
large enough, we can get a good estimate of with good probability. This will suffice to distinguish uniform from L2-far from uniform.
- this will imply that setting
I think the main interesting part is bounding
If we let
We can break this into 3 parts:
- If
are all distinct then - You could also imagine
. - But the dominant term is
. - but it’s manageable.
Next, you can use this L2 tester to get an L1 tester. Specifically, multiplicatively approximating L2 norm can give additive approx on L1 norm.
To summarize,
We have this estimate
If we want an additive
If we want a
distribution testing part 2 — closeness testing
Recall from last time — we had a pretty nice estimator for
We used this to distinguish
Now we generalize to the following question:
Suppose we know
, and get samples from . Can we tell apart vs not?
- best query complexity is
. I think this was on the hw.
Even trickier question:
You get samples from both
. Can you tell apart VS ??
- this one is
. kind of surprising how much harder this is than if is known.
Trickiest question: (tolerant testing)
VS ??
- apparently this one the answer is
. wow that’s tough!
Anyways, back to the non-tolerant testing setting.
We already know how to estimate
PROBLEM —
- Suppose we take
samples and let be the number of times we got element . aren’t independent! more of one means probably less of others.
Solution —
- Don’t fix the number of samples. Instead, choose it randomly from Poisson distribution.
Interesting Fact: The following two things are actually the same
- Sampling
and then taking samples - Sampling
for each and then taking copies of and permuting things.
I think this is because
Recall — Poisson distribution is supposed to model something that happens with some rate over some interval, and the events are independent.
Reducing to the low L2-norm case
Recall — we had some algorithm for estimating
PROBLEM:
This looks bad if
SOLUTION:
We’ll transform
Flattening
Recall: if
Procedure:
-
samples from . -
number of times appears in . -
Now make a new domain, with
copies of for each . -
New distribution: choose random
, then choose random copy of to ouput.
We’re going to use one
Claim:
Proof: It just turns out that this is how the Poisson distribution works.
Theorem: given
Cor only need
Full algorithm, with running time
- Flatten using
samples. - This results in L2 norm being
whp
- This results in L2 norm being
- Run tester on flattened guys
Cost:
nice.
distribution testing part 3 — monotone
- We say a distribution
on is monotone if for all . - Want to test: monotone VS L1 far from monotone.
- Goal:
queries.
Birge Decomposition:
Split
Flattened distribution:
- Pr of each guy is the average Pr of an element in that guys bucket
Birge’s theorem:
If
monotone, then are L1 close.
Idea for an algorithm:
- Let
be an estimate of the Birge Flattened distribution of our distribution - If
isn’t close to monotone then REJECT. - Else, check that
are close. REJECT if not, ACCEPT if are.
Analysis:
Claim 1: If
Proof:
monotone, then monotone, ‘s are close to ‘s, so , so approx monotone. - Also,
because . - So we’ll accept.
Claim 2: If tester passes whp then
Proof
ok, but we haven’t even talked about how to do tolerant testing of whether
ok. neat.
Proof of Birge’s theorem 0. no err on length 1 intervals
- If there are any intervals of length at most
then there are at least size 1 intervals. - Let
denote the max pr on -th interval, and denote length of -th interval - Then ERROR is at most
. because of how we did the dyadic cuts.
Property Testing on Dense Graphs
I think there might be some ridiculous theorem that says something like “the properties which can be tested efficiently are exactly the hereditary properties” where I say ridiculous because it invokes Szemeredi Regularity Lemma. But I think even if this is true, it’s still an interesting question “how good of a tester can I get?” This is just a preface to motivate why we’re going to spend some time on testing bipartiteness even if this is a hereditary property. Anyways today we’re going to talk about bipartiteness.
Testing Bipartiteness
Plan:
- Suppose our graph really is far from bipartite. Then, for any fixed partition, if we sample a couple of edges, it’s quite likely that we’ll find some edges that violate that partition — an
-fraction of edges violate the partition so something on the order of gives us a good shot. - However, union bounding over
many partitions isn’t going to fly with the above approach. - So we find a much smaller set of vertex partitions, which are “dense” in the space of all vertex partitions.
Here’s our smaller set of vertex partitions:
- Choose a random set
of size . - For every partition
of form a partition of as follows: - If
has neighbors in both and then output “bad partition” - If
has neighbors in at most one of , then stick it on whichever side it doesn’t have neighbors to.
- If
In order for this to be good, I think we’d approximately need the following lemma:
Lemma that I’d want:
If
Why I want this Lemma: We definitely have the following thing:
Fact:
If
So if the Lemma that I wanted were true, then we just need to get a good approx for number of violating edges in each of these partitions. Which I think is pretty doable.
Here’s why I think the lemma is true:
- There are two types of vertices.
- Dumb vertices have degree at most
. tbh we can just pretend these vertices don’t exist because we’re allowed to cut edges. - The other type of vertex is the type of vertex where if you sample
random vertices from the graph, it’s quite likely that one of those guys is connected to this vertex. Where quite likely probably means Pr 1-eps/100 here. - So, we don’t care about dumb vertices, and non-dumb vertices should be placed on the correct side.
And yup that’s what Ronnitt did too. Very nice!
Triangle-freeness
Today we’re going to talk about testing for triangle-freeness. Will abbreviate szemeredi reg lemma to SRL here.
Recall: vertex sets
Lemma:
If all pairs in
SRL:
Equipartition into
Now the property testing question:
- Distinguish between
triangle free and must remove edges to kill all triangles.
How we do it:
Triangle Removal Lemma
This means that the simple tester of just choosing some random triples and checking if they make a triangle works!
ok, proof?
- We do a regularity equipartition into
parts. - CLEAN we remove a small number of edges:
- Delete edges within parts
- Delete edges between irregular parts
- Delete edges between low density parts
- If
was far from -free then must still have a triangle. - But now, one triangle implies cubicaly many triangles!