A principle of interacting with people that is highly under-utilized is asking people for help. It’s possible to go too far with this, but I suspect you aren’t. The easiest way to employ this interacting with people strategy is, when interacting with someone you can think about the set of problems that you’re currently dealing with and talk about them with other people. A note of caution is that it’s bad to try to put responsibility for any decisions on other people — this is not responsible. But this is a service that most people are happy to provide and sometimes it’ll be useful. In my latest instantiation of trying this I asked some people for some cool math problems, because I wanted to get some exposure to some different topics. This saved me a lot of time trying to find good problems. Thanks!
Part 1 — Nathan — Complexity Theory
info theory basic facts
Let
This is saying, the average info you get from looking at a random subset of the coordinates of
This is obviously tight: suppose that the entropy of
crisp example of DKL asymmetry:
if truth is
NQ1: Prove that IP = PSPACE. note — I didn’t figure this one out — ended up just looking at wikipedia
The direction
ok wikipedia suggested warming up by thinking about sharp-SAT.
The Sharp-SAT problem is, given a formula and a number
Here’s how we’re going to do it.
Fix a formula
The protocol is as follows:
- Ask the Prover for the value of
--- this is supposedly the number of SAT assignment of , if the Prover is being honest. The Prover hands over some number which may or may not actually be . (PS: the prime doesn’t mean derivative) - Ask the Prover to give you coefficients for the degree
polynomial ; the Prover hands over some polynomial which may or may not be . 2. Check that . 3. This ensures that if is a lie, then . - Now, the verifier chooses a random
and tells the prover about it. - Because
is a low degree polynomial, the chance that is pretty low. In particular low enough that we can union bound over all steps of the proof and assume that it never happens.
- Because
- Anyways we kind of just continue on like this.
- The prover sends us
. - We check for consistency with
. - If
was a lie, so if .
- The prover sends us
- Finally at the end the prover will tell us some value
and we can literally just check whether it’s true or not.
TQBF is in PSPACE.
We’re going to do something pretty similar, with a minor twist.
Let’s arithmetize the formula again.
We’re going to define
In order to get this what we can do is define
if the quantifier in question was a
This is great but it doesn’t quite work because the degree blows up too much.
Luckily there is a way to reduce the degree. After every quantifier we intersperse these things which are like replace
not just for
nice.
NQ0: Prove the time hierarchy theorem + prove halting problem is undecidable. pf: Diagonalization
NQ2 Claim:
Proof: Standard padding argument + Time hierarchy theorem.
Assume the claim is false, i.e.,
NQ3 Claim 1:
Show that every function
There’s a pretty simple way to make a circuit with
NQ3 Claim 2:
Most functions need at least
NQ4
recall that in an arthur-merlin protocol, arthur first chooses some random bits to send to merlin, then merlin responds with a proof, which arthur verifies through some probablistic polynomial time algorithm. a language is in AM if there’s such a protocol with two-sided error 1%. you could also, for any k, define
Proof
For convenience I’m going to work with a complexity class which I call
I’d like to show that
Procedure 1:
Arthur sends randomness r1
Merlin responds with proof pi1
Arthur runs a (deterministic) procedure on r1,pi1 and outputs accept / reject.
Procedure 2:
Arthur sends randomness r1
Merlin responds with proof pi1
Arthur sends randomness r2
Merlin responds with proof pi2
Arthur runs a deterministic procedure on r1,r2,pi1,pi2 and outputs accept / reject.
Okay, how do we do it?!
Arthur’s procedure is as follows:
Let n^c be the maximum allowed length of pi1 in the two round protocol. I can assume that this is polynomial because otherwise Arthur can't even recieve pi1!
I guess you could think of some model where Arthur just gets random access to pi1? But I think we're not doing that.
Anyways, send Merlin r1, r21,r22,r23...,r2,n^c (all at once)
And request merlin to produce pi1, pi21,pi22,...,pi2n^c
such that in the 2 round procedure we would've accepted this stuff
Arthur then runs the 2 round protocol on pi1,pi2k,r1,rik for each value of k.
Arthur accepts if more than half of the 2 round protocol things accept, and rejects else.
Observation 1
For a statement in the language, say that
is misleading if there aren’t any such that it’s 90% likely over choice of that there’s a proof such that Arthur accepts . For a statement outside of the language, say that
is misleading if there is some such that there’s more than a chance over choice of that there exists so that Arthur accepts . Theorem: the chance that
is misleading is at most .
Proof: Otherwise it’d violate our two-sided error bounds.
Lemma 2
Fix
which isn’t misleading for statement X, and fix some . If you generate many ‘s and ask for ‘s with respect to all of them, then if X is true with probability we’ll have at least of the pairs are accepted by Arthur (if Merlin’s on the ball) and if X is false then with probability we’ll have at most of the proofs accepted by Arthur, no matter how hard Merlin tries.
Proof: Chernoff bouund
Now we union bound over all proofs
In conclusion this means that we have a procedure that is great and it has 2-sided error
Note that the blow-up in proof complexity is like, if the proof complexity before was like
But we haven’t ruled out the possibility that
NQ5
You could define a k-round interactive proof to use private randomness. That is,
Part 2 — Alexis — information theory
Q1
Fix directed graph
Proof
Let
Let
To show this we’ll demonstrate a distribution on
- Sample
and to be uniformly random wedges, but they are correlated (we condition on their first vertex being the same). - Output
. This has the required edges . - And it has the required entropy.
Q2
Let
Then
This is because
Finally,
by writing down the formula for divergence or thinking of divergence as suprise.
Here’s a cute application of this fact:
Q2.b Find
Observe that
by the problem about sorting. Neat.
Q3
For some reason I had trouble finding a nice definition of mutual information so I’m putting it here for all future people so that you can find it easily. It’s quite intuitive, it’s just the shared randomness amongst all three rvs.
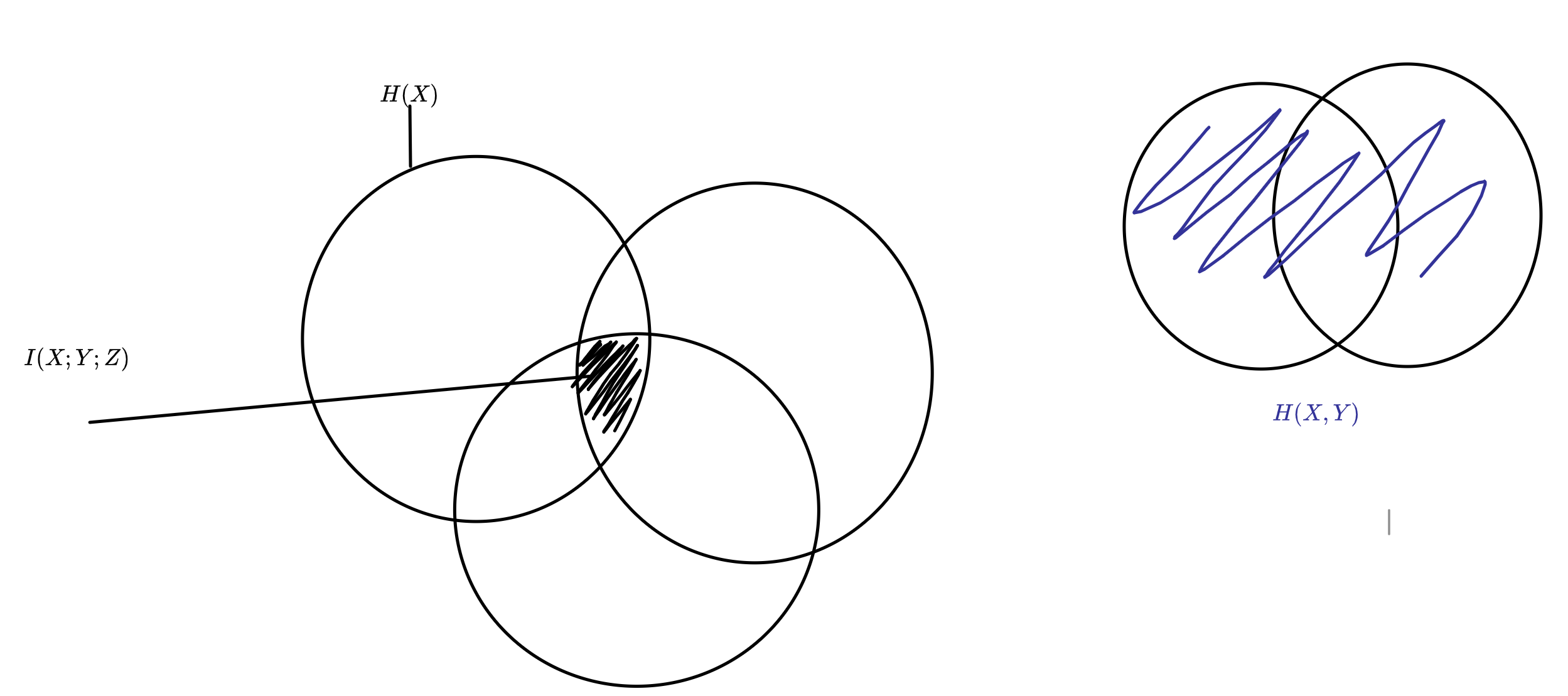 Anyways, on to the question.
Anyways, on to the question.
Q3a
Suppose
(Note the difference between commas and semi-colons.)
For this problem I thought it’d be helpful maybe to know what the entropy in a Gaussian is. You can do some integral to find it — I just googled it.
where
ok that didn’t directly help me I guess.
anyways, I had a long detour about normal random variables.
Apparently if
Where
Another thing I realized is that it’s hard to sqrt the covariance matrix. not literally hard, I think there’s a nice algo for it. but just hard for me.
Here’s another way of thinking about it.
Anyways I kind of give up on this problem for now.
Q3b
The most classic question ever — give example of
Q3c
Give an example where
some more information theory
Here’s an interesting question. I’ve done the computation but don’t get what it means yet.
Suppose you have a noisy channel. Specifically it works like this:
always. goes to a random output.
Q: What is the capacity of this channel. I.e., how much information can you send in this channel?
It turns out that the right input distribution is as follows:
A curious fact about this choice of
Question: explain why this needs to be the case. Like:
- Why does the best
balance these expressions - Why is the mutual info captured by this KL divergence?
okay actually there’s a pretty simple explanation for all of this: First of all,
(you can see this identity by just writing out the definition of KL divergence). Anyways, this implies, by splitting up a sum,
So at this point we at least understand why, if the
I still don’t have a great understanding of why we’d want the surprises to be the same…
digression TV distance: